In the world of enterprise data ingestion and search indexing, Apache ManifoldCF has long stood as a solid, battle-tested framework. Born in the era of web portals, custom XML configurations, and bare-metal servers, ManifoldCF excels at connecting diverse repository systems (Alfresco, SharePoint, CMIS, Documentum, file shares) to search indexers like Apache Solr, Elasticsearch, and OpenSearch.
However, as software architecture shifted toward cloud-native microservices and AI-driven applications such as Retrieval-Augmented Generation (RAG) and vector search, the legacy model of ManifoldCF began showing its age.
Enter Spring-Manifold Next-Gen (probably Apache ManifoldCF 3.x in the future), a modern, high-performance reboot designed to meet these challenges. Built on Java 25 (Preview Features) and the Spring Boot 4 ecosystem, this next-generation platform updates the core crawling orchestrations, decouples document processing using Apache Kafka and Apache Tika, integrates AI capabilities via Spring AI / Ollama, and introduces lightweight high-concurrency patterns.
This article dives deep into the technical improvements of Spring-Manifold Next-Gen over the classic Apache ManifoldCF v2.x. We'll focus on three main areas:
Spring Framework & Boot Ecosystem Adoption
Modern Design Patterns (Sealed Interfaces, Records, and the Claim Check Pattern)
High-Concurrency, Scalability, and Monitoring (Virtual Threads, Structured Concurrency, Apache Kafka, pgvector)
Architectural Paradigm Shift: Spring Boot Adoption
The primary difference between classic Apache ManifoldCF and Spring-Manifold Next-Gen lies in their architectural foundations. Classic ManifoldCF relies on a custom servlet-based runtime, static service locators, and manual configuration management.
The Next-Gen project completely rebuilds these components around Spring Boot.
Spring Dependency Injection vs. Legacy Static Locators
In classic ManifoldCF, components are initialized manually, often passing around a thread context to locate system utilities:
// Classic ManifoldCF Service LocationIThreadContext threadContext = ThreadContextFactory.make();IJobManager jobManager = JobManagerFactory.make(threadContext);This model makes unit testing and custom integration difficult because components are tightly coupled to the underlying database engine and a global thread context.
In Spring-Manifold Next-Gen, components are first-class Spring beans. Dependency injection is handled clean and declaratively through constructor injection, making the architecture highly modular and testable:
// Spring-Manifold Next-Gen Constructor Injection@Componentpublic class IngestionConsumer { private final OutputConnector outputConnector; public IngestionConsumer(OutputConnector outputConnector) { this.outputConnector = outputConnector; }}Decoupled Headless REST APIs vs. Embedded HTML Connectors
One of the most striking legacy aspects of classic ManifoldCF is the tight coupling between the user interface and connector logic. Connectors in Apache ManifoldCF are required to render their own HTML forms for configuration screens by writing raw HTML markup strings directly to an output stream:
// Classic ManifoldCF Connector UI Methodpublic void outputConfigurationBody(IThreadContext threadContext, IHTTPOutput out, Locale locale, ConfigParams parameters, String tabName) throws ManifoldCFException, IOException { out.print("<table class=\"displaytable\">\n"); out.print(" <tr>\n"); out.print(" <td class=\"description\"><nobr>Server port:</nobr></td>\n"); out.print(" <td class=\"value\"><input type=\"text\" name=\"port\" value=\"" + port + "\"/></td>\n"); out.print(" </tr>\n"); out.print("</table>\n");}This makes UI updates difficult, prevents headless operations, and violates the separation of concerns.
Spring-Manifold Next-Gen addresses this by separating the frontend from the backend:
Headless REST API: sm-runtime module expose clean, JSON-based REST endpoints via Spring MVC controllers.
Modern SPA Frontend: The admin dashboard is a standalone Single Page Application built on React, Vite, and Tailwind CSS, which communicates with the REST controllers.
Pure Logic Connectors: Interfaces like RepositoryConnector and OutputConnector contain only data ingestion and mapping logic, with no UI-rendering code.
Modern Design Patterns & Java 25 Features
By leveraging Java 25, Spring-Manifold Next-Gen introduces type safety, record-driven models, and modern data-flow patterns.
Sealed Classes and Pattern Matching
Classic ManifoldCF relies heavily on standard polymorphism and manual cast expressions. Spring-Manifold Next-Gen leverages Java 25 Sealed Interfaces and Records to model domain states safely.
For instance, the result of a document scan is modeled as a sealed interface, below the first version of the ScanResult.java created for this purpose:
package org.apache.manifoldcf.core.result;public sealed interface ScanResult permits ScanResult.Success, ScanResult.Failure, ScanResult.Ignored { record Success(String documentId, String version) implements ScanResult {} record Failure(String documentId, Throwable error) implements ScanResult {} record Ignored(String documentId, String reason) implements ScanResult {} default String summarize() { return switch (this) { case Success s -> "Successfully scanned: " + s.documentId() + " (v: " + s.version() + ")"; case Failure f -> "Failed to scan: " + f.documentId() + " due to " + f.error().getMessage(); case Ignored i -> "Ignored: " + i.documentId() + " Reason: " + i.reason(); }; }}This approach provides several advantages:
Domain Model Clarity: The compiler enforces that only ‘Success’, ‘Failure’, and ‘Ignored’ records can implement ScanResult.
Exhaustive Switches: The pattern matching switch statement does not require a ‘default’ case; if you add another permitted subclass, the compiler will alert you to handle it, preventing runtime bugs.
3. High Performance, Concurrency, and Scalability
Modern ingestion engines need to scale out horizontally to handle millions of documents, and scale up vertically to process text extraction, chunking, and AI embeddings efficiently.
Decoupled Processing via Apache Kafka & The Claim Check Pattern
Classic Apache ManifoldCF uses the database itself as the central task queue. Worker threads poll database tables at short intervals to find documents pending processing:
SELECT documentid FROM jobqueue WHERE status = 'PENDING' FOR UPDATE;This pattern creates severe database contention and locking issues under heavy load. To coordinate processes across machines, ManifoldCF requires distributed locking setups using ZooKeeper or shared filesystems.
Spring-Manifold Next-Gen resolves this database bottleneck by introducing an event-driven architecture based on Apache Kafka and the Claim Check Pattern:
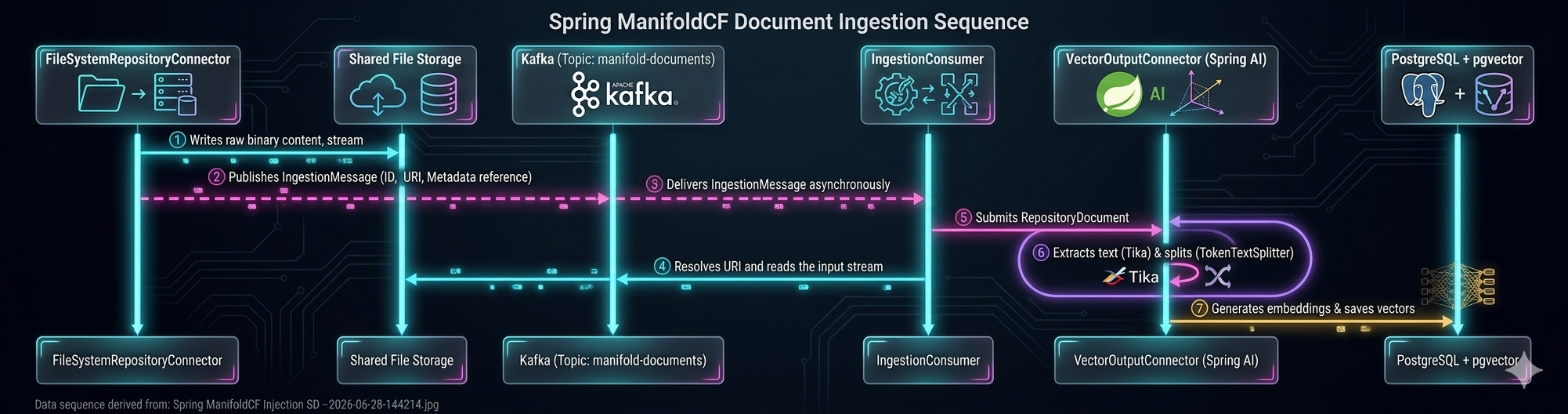
Event driven architecture based on Claim Check Pattern introduced with Spring-Manifold Next-Gen
Lightweight Messages: Rather than sending large document contents directly over Kafka, the FileSystemRepositoryConnector writes the files to a shared storage directory (e.g. NFS, S3/MinIO) and publishes a small IngestionMessage containing only the metadata references and file URI.
Asynchronous Consumers: In the ‘sm-runtime’ module, the ‘IngestionConsumer’ listens to the topic via KafkaListener.
Decoupled Heavy Lifting: The consumer retrieves the raw file stream, parses the content with Apache Tika, runs text splitting, requests embeddings (via Ollama), and writes the vectors to pgvector. This allows you to scale the consumer group independently of the repository scanners.
Lightweight Concurrency: Java 25 Virtual Threads & Structured Concurrency
Classic ManifoldCF manages thread pools manually. If a connector blocks on network I/O, the OS thread is parked, limiting scalability.
Spring-Manifold Next-Gen is designed for modern Java runtimes. By configuring ‘VirtualThreadConfig.java’, the application directs asynchronous tasks to Virtual Threads:
@Configurationpublic class VirtualThreadConfig { @Bean(name = "virtualThreadExecutor") public AsyncTaskExecutor virtualThreadExecutor() { return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor()); }}Additionally, the scanning and orchestration logic utilizes Java 25 Structured Concurrency to manage concurrent subtasks. Look at how the ‘JobOrchestrator’ runs a scan job:
public void runJob(RepositoryConnector repositoryConnector, OutputConnector outputConnector, String path) { try (var scope = StructuredTaskScope.open()) { StructuredTaskScope.Subtask<List<ScanResult>> scanTask = scope.fork(() -> { List<ScanResult> results = new ArrayList<>(); repositoryConnector.scan(path) .flatMap(doc -> { try { IngestionMessage msg = new IngestionMessage( doc.id(), doc.uri(), doc.metadata(), doc.acl(), doc.lastModified().toString() ); // Publish metadata reference to Kafka kafkaTemplate.send(KafkaConfig.TOPIC_NAME, doc.id(), msg).get(); return Mono.just((ScanResult) new ScanResult.Success(doc.id(), "1.0")); } catch (Exception e) { return Mono.just(new ScanResult.Failure(doc.id(), e)); } }) .doOnNext(results::add) .blockLast(); return results; }); // Block until subtasks finish (joining the thread lifetimes) scope.join(); List<ScanResult> scanResults = scanTask.get(); // Process results... } catch (Exception e) { log.error("Job execution failed: ", e); }}Furthermore, the ‘FileSystemRepositoryConnector’ scans directories in parallel recursively, spawning subtasks within a structured boundary:
private void scanDirectory(Path dir, FluxSink<RepositoryDocument> sink) throws InterruptedException { try (var scope = StructuredTaskScope.open()) { try (DirectoryStream<Path> stream = Files.newDirectoryStream(dir)) { for (Path entry : stream) { if (Files.isDirectory(entry)) { // Fork a virtual thread for each sub-directory scope.fork(() -> { scanDirectory(entry, sink); return null; }); } else if (Files.isRegularFile(entry)) { RepositoryDocument doc = createDocument(entry); sink.next(doc); } } } scope.join(); // Clean join prevents thread leakage }}Structured Concurrency guarantees that the lifetime of spawned virtual threads is strictly tied to the 'try-with-resources’ block. If a parent task is cancelled, all child subtasks are automatically aborted, avoiding orphan threads.
4. Modern Enterprise Scaling & Monitoring
The comparative architectural attributes below highlight the structural differences between the two systems:
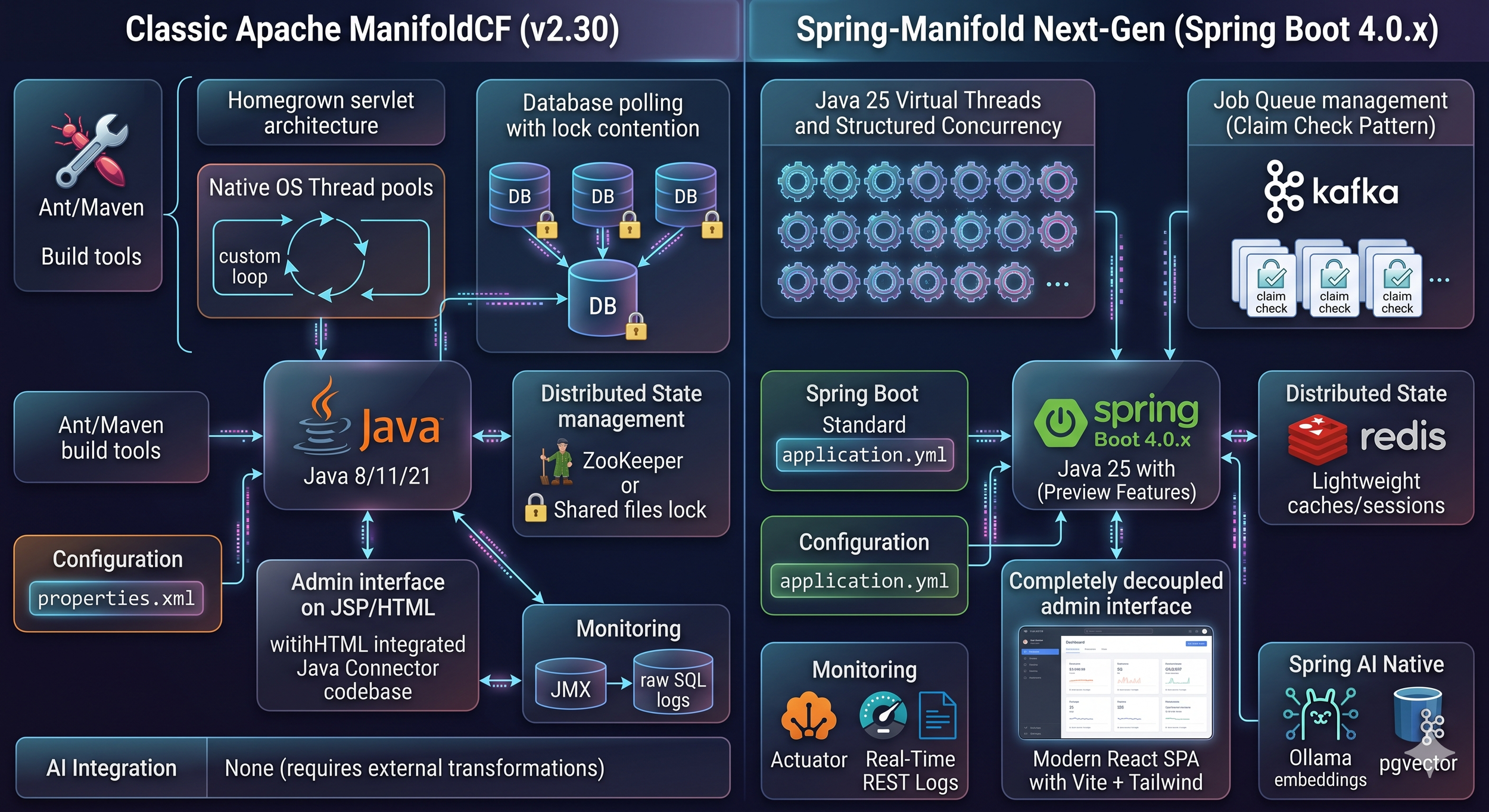
Highlights of the architectural differences between ManifoldCF Classic and Next-Gen
Built-in Infrastructure Monitoring
Spring-Manifold Next-Gen exposes system statistics and mock telemetry directly in the development dashboard via SystemController. The application monitors the availability of PostgreSQL, Redis, and Ollama (Work in progress… ).
In production, Spring Boot's actuator endpoint (‘/actuator/health’) will be configured to provide health checks to Kubernetes, NGINX, or prometheus scraping targets out of the box, facilitating modern container observability.
Conclusion: Ready for the Future
Spring-Manifold Next-Gen is more than just a dependency upgrade; it is a structural redesign of Apache ManifoldCF. By replacing database polling loops with Apache Kafka, replacing OS thread-blocking with Java 25 Virtual Threads, and separating business logic from UI code, it provides a performant foundation for data ingestion.
With native support for Spring AI, pgvector, and Ollama, this platform is well-suited for RAG pipelines and modern AI search architectures.
To explore the codebase or run the Next-Gen platform locally, check out the project's README.md file.
Check out our contribution guidelines at CONTRIBUTING.md on the GitHub page:
https://github.com/OpenPj/spring-manifold-next-genLet's build the future of open source document ingestion together.
Drop a comment, open an issue, or submit a pull request!
